Video: Investigating Your Container Recommendations
Video: Investigating Your Container Recommendations
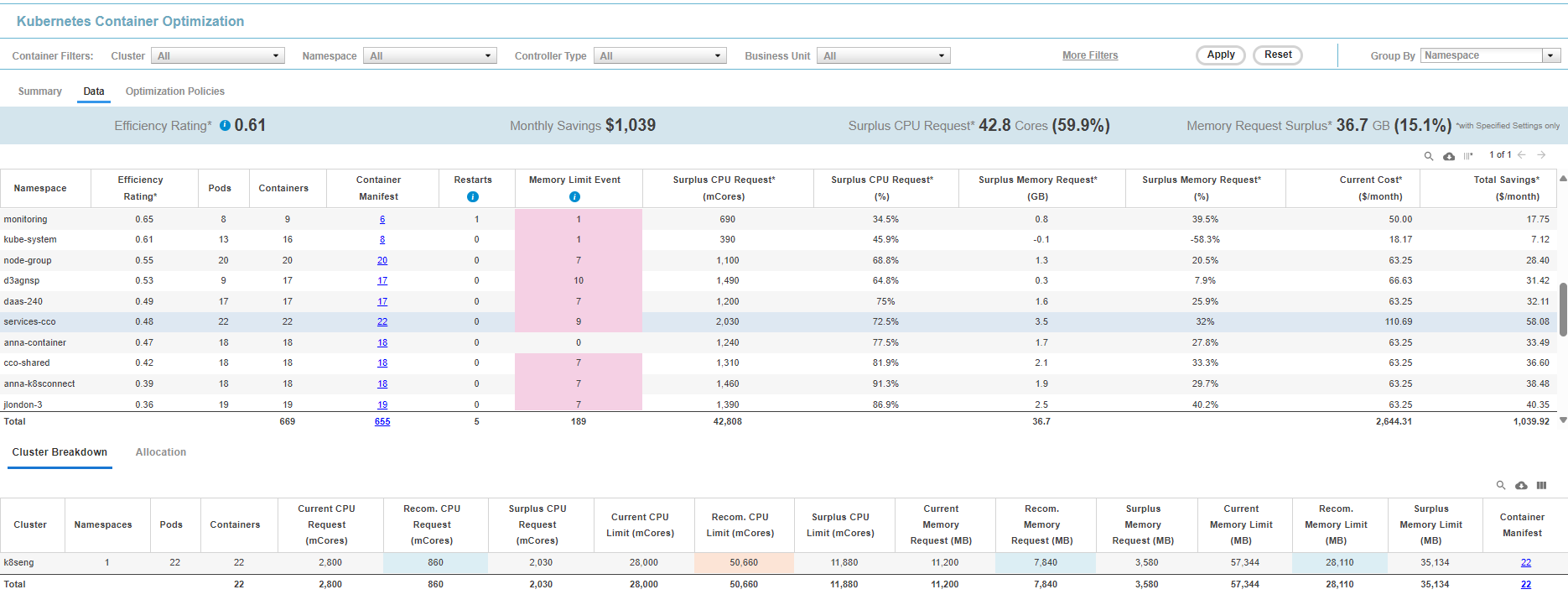
Figure: Kubernetes Container Optimization - Data Tab (hover over image to expand)
Figure: Kubernetes Container Optimization - Data Tab (hover over image to expand)
Grouping and Filtering Your Container Data
You can group and filter your data using the following options:- Group By—See Using the Group By Feature;
- Container Filter—See Using Container Filters.
Summary Banner
Key metrics are displayed in a banner at the top of the report. If you have applied filters the totals displayed in this summary reflect the filtered results. The values, in the Summary bar are not affected by the Group By feature. See Reviewing the Summary Tab for details of the key metrics.Data Controls
The controls, in the upper right corner of the page, provide options for managing and viewing your data more effectively. See Data Controls on Tabular Reports for more details.Viewing the Tabular Data - Top Pane
The breakdown of the data for your aggregated container environments is displayed on the top pane of this tab. You can control how the data is displayed in this table using the Group By feature. The Group By setting is used in the first column and data is retrieved and displayed accordingly. For example, if you wanted to group the data based on Business Unit, Densify displays the analyzed data sorted based on the value of the Business Unit resource tag. See Using the Group By Feature. The top table provides a breakdown as follows:Table: Kubernetes Container Optimization - Data Tab Columns
Table: Kubernetes Container Optimization - Data Tab Columns
Column(s) | Description |
|---|---|
Group By selection: Application | <br/>Business Unit | etc. | The first column is determined by your Group By selection. You can control how the data is displayed in this table using the Group By feature. Your Group By selection is used in the first column and data is retrieved and displayed accordingly. See |
Efficiency Rating* | The Efficiency Rating provides an indication of the health of your aggregated environment. The value is indicated in red, when it is greater than 1.
By default, the table is sorted by the Efficiency Rating, in descending order. You can sort the content of the table by any column, by clicking on the column header. The asterisk on this value indicates that containers with unspecified values are not included in this calculation. |
Clusters | The total number of clusters on which the Application | Business Unit | etc. is running. The grouping is defined in the first column. You can change the Grouping options using the Group By feature. This column is hidden by default. You can enable it for display, as required. See Data Controls, above. |
Namespaces | The total number of namespaces on which the Application | Business Unit | etc. is running. The grouping is defined in the first column. If the data is grouped by namespace, then the total number of namespaces with the same name are listed here. Namespaces must be unique within a cluster but you can reuse a name in a different cluster. i.e. you can have a “monitoring” namespace in each of your clusters. This column is hidden by default. You can enable it for display, as required. See Data Controls, above. |
Pods | The total number of pods on which the Application | Business Unit | etc. is running. |
Containers | This is the number of unique containers on which the Application | Business Unit | etc. is running. If the data is grouped by namespace, then the total number of containers with the specified namespace are listed here. |
Container Manifest | This is the number of manifests that reference the Application | Business Unit | etc. The number of instances listed in this column is a hyperlink that takes you to the Kubernetes Container Optimization > Analysis tab, for the selected grouping. i.e. Only the specific systems, as indicated by the count in the originating table cell, are shown on the Kubernetes Container Optimization > Analysis tab. See |
Optimal | Identified Risk | Savings Opportunity | Risk and Savings | Size from Unspecified | These 5 columns provide a breakdown by recommendation type.
The number of instances listed in this column is a hyperlink that takes you to the Kubernetes Container Optimization > Analysis tab, for the selected grouping. i.e. Only the specific systems, as indicated by the count in the originating table cell, are shown on the Kubernetes Container Optimization > Analysis tab. See Values are colour-coded for improved readability. Colour coding is listed in Container Optimization Types. Some of these column are hidden by default. You can enable then for display, as required. See Data Controls, above. |
Percent Optimal (%) | This is the percentage of total containers that are sized correctly. (Optimal Count /Total Systems) This column is hidden by default. You can enable it for display, as required. See Data Controls, above. |
Container Manifests with Restarts - Last Day | The number of container manifests in the selected grouping with containers that were restarted in the last day. Only containers that were part of the selected group AND not part of another group, in the last day, are counted. |
Container Manifests with Memory Limit Events - Last Day | The number of container manifests in the selected grouping which have exceeded the working set memory limit, in the last day. |
Surplus CPU Request(Cores)* | This is the number of surplus CPU cores for the selected Application | Business Unit | etc. Calculated as (Current CPU Request - Recommended CPU Request) The asterisk on this value indicates that containers with unspecified values are not included in this calculation. |
Surplus CPU Request (%)* | This is the number of surplus CPU cores for the selected Application | Business Unit | etc. expressed as percentage. Calculated as (Surplus CPU Request/Current CPU Request)*100 The asterisk on this value indicates that containers with unspecified values are not included in this calculation. |
Surplus Memory Request (GB)* | This is the amount of surplus memory for the selected Application | Business Unit | etc. Calculated as (Current Memory Request - Recommended Memory Request) The asterisk on this value indicates that containers with unspecified values are not included in this calculation. This column is hidden by default. You can enable it for display, as required. See Data Controls, above. |
Surplus Memory Request (%)* | This is the amount of surplus memory for the selected Application | Business Unit | etc. expressed as a percentage. Calculated as (Surplus Memory Request/Current Memory Request)*100 The asterisk on this value indicates that containers with unspecified values are not included in this calculation. |
Current Cost ($/month)* | The estimated cost is the aggregate cost of all of the services in the selected account, as indicated by Total Services for each row. The asterisk on this value indicates that containers with unspecified values are not included in this calculation. |
Net Savings ($/month) * | If the recommendations are implemented, the net savings indicated here can be achieved. This value is calculated as the current estimated cost minus the estimated cost of the recommended instances. The asterisk on this value indicates that containers with unspecified values are not included in this calculation. |
Total | The totals at the bottom of the table indicate the total for each column, for all pages, if you have a multi-page report. Vertical scroll bars may be displayed to scroll through the entire list, so lower rows may be momentarily hidden behind the row of Totals. This count is a hyperlink that takes you to the K page for the selected grouping. i.e. Only the specific systems, as indicated by the count in the originating table cell, are shown in the Kubernetes Container Optimization Details page. For more information, see |
Cluster Breakdown Tab - Lower Pane
The details, of the row selected in the top pane, are expanded and displayed on two tabs on the lower pane. The Cluster Breakdown tab provides a subset of the information from the top of the page, for only the selected row, expanded by Cluster and sorted by cluster name.Figure: Cluster Breakdown and Allocation Tabs (hover over image to expand)
Figure: Cluster Breakdown and Allocation Tabs (hover over image to expand)
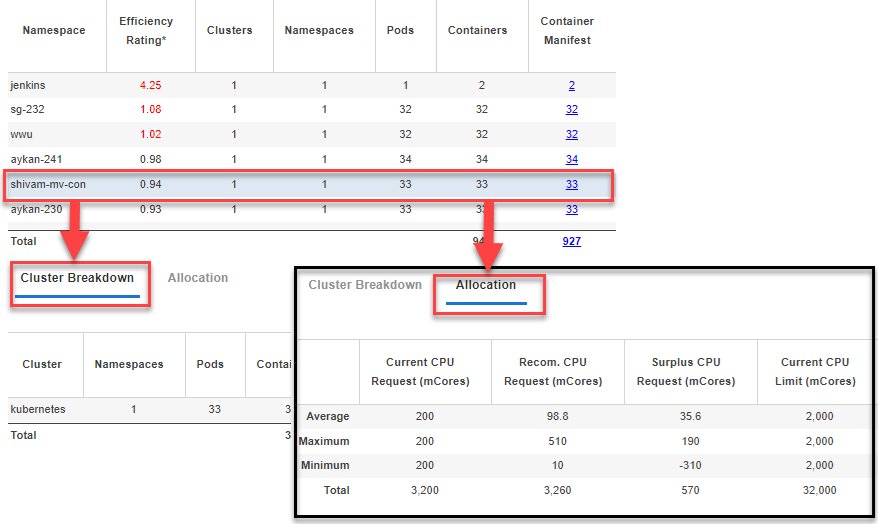
Table: Columns in the Cluster Breakdown Tab
Table: Columns in the Cluster Breakdown Tab
Column | Description |
|---|---|
Cluster | This is the name of the cluster. |
Namespaces | This is the number of unique namespaces in the cluster that are within the grouped selection. |
Pods | This is the number of unique pods within the grouped selection. |
Containers | This is the number of unique containers based on the grouped selection. |
Current CPU Request (mCore) | This is the aggregated total current CPU request for the containers in the selected cluster. Containers with unspecified CPU or memory requests and/or limit values are indicated with a dash (-). |
Recommended CPU Request (mCore) | This is the aggregated total CPU Request recommended for the containers in the selected cluster. Values are colour-coded for improved readability. Colour coding is listed in Container Optimization Types. |
Surplus CPU Request (mCore) | This is the aggregated total CPU request surplus. This value can be negative (at risk) or a positive value. |
Current CPU Limit (mCore) | This is the aggregated total current specified CPU limit for the containers in the selected cluster. Containers with unspecified CPU or memory requests and/or limit values are indicated with a dash (-). |
Recommended CPU Limit (mCore) | This is the aggregated total CPU limit recommended for the containers in the selected cluster. Values are colour-coded for improved readability. Colour coding is listed in Container Optimization Types. |
Surplus CPU Limit (mCore) | This is the aggregated total CPU limit surplus for the selected cluster. This value is calculated as (Current CPU limit - Recommended CPU limit) * Current Count) of the filtered records. Containers with unspecified CPU or memory requests and/or limit values are indicated with a dash (-). |
Current Memory Request (MB) | This is the aggregated total current memory request for the containers in the selected cluster. Containers with unspecified CPU or memory requests and/or limit values are indicated with a dash (-). |
Recommended Memory Request (mCore) | This is the aggregated total memory request recommended for the containers in the selected cluster. Values are colour-coded for improved readability. Colour coding is listed in Container Optimization Types. |
Surplus Memory Request (mCore) | This is the aggregated total memory request surplus. This value is calculated as (Current Memory Request - Recommended CPU | Memory Request) * Current Count) of the filtered records. Containers with unspecified CPU or memory requests and/or limit values are indicated with a dash (-). |
Current Memory Limit (MB) | This is the aggregated total current specified memory limit for the containers in the selected cluster. Containers with unspecified CPU or memory requests and/or limit values are indicated with a dash (-). |
Recommended Memory Limit (MB) | This is the aggregated total memory limit recommended for the containers in the selected cluster. Values are colour-coded for improved readability. Colour coding is listed in Container Optimization Types. |
Surplus Memory Limit (MB) | This is the aggregated total surplus memory limit. This value is calculated as (Current Memory limit - Recommended Memory limit) * Current Count) of the filtered records. Containers with unspecified CPU or memory requests and/or limit values are indicated with a dash (-). |
Container Manifest | This is the number of manifests that reference the specified cluster etc. The number of instances listed in this column is a hyperlink that takes you to the Kubernetes Container Optimization > Analysis tab, for the selected grouping. i.e. Only the specific systems, as indicated by the count in the originating table cell, are shown on the Kubernetes Container Optimization > Analysis tab. See |
Allocation Tab - Lower Pane
The allocation details of the row, selected in the top table is expanded and displayed on this tab in the lower part of the page. The Allocation tab provides more detailed allocation data for the selected row. Based on the row selected in the top table, the following values are calculated:- Average—for the selected row the average is calculated as (total / # of containers);
- Maximum—The maximum value of all the items for the selected row;
- Minimum—The minimum value of all the items for the selected row;
- Total—The total values of all the items for the selected row.
Table: Columns in the Allocation Tab
Table: Columns in the Allocation Tab
Column(s) | Description |
|---|---|
Current | Recommended CPU Request | Limit | These 4 columns indicate the current and recommended CPU requests and limits. The average, maximum, minimum and total values are shown for the containers in the selected row. |
Surplus CPU Request | Limit | These 2 columns indicate the surplus or deficit CPU requests and limits. If this is an identified risk recommendation the value may be negative indicating that additional resources are required for this cluster. This value is calculated as (Current vCPU request | limit - Recommended vCPU request | limit) * Current Count) of the filtered records. Systems with a ‘Terminate’ recommendation, are excluded from the calculation in the ‘Recommended’ columns. If all of the systems in the group have a ‘Terminate’ recommendation, the values in Recommended columns will be indicated as a dash (-). Containers with unspecified CPU or memory requests and/or limit values are indicated with a dash (-). |
Current | Recommended Memory Request | Limit | These 4 columns indicate the current and recommended memory requests and limits. The average, maximum, minimum and total values are shown for the containers in the selected row. |
Surplus Memory Request | Limit | These 2 columns indicate the surplus or deficit memory requests and limits. If this is an identified risk recommendation the value will be negative indicating that additional resources are required for this cluster. Containers with unspecified CPU or memory requests and/or limit values are indicated with a dash (-). |
Predicted Uptime (%) | The predicted uptime (%) for a container is based on the percentage of hours that CPU utilization data is present in the historical interval, that is specified in the policy settings. |
# of Containers | The number of containers on which the reported data is based. |
# of Nodes | The number of nodes on which the containers are running. |
- Systems with missing data are excluded from the calculations;
- If there is no data or values are unspecified for a whole group of systems, this is indicated as a dash (-);